Vi ricorderete che nei precedenti articoli sul tema generale del Data Management abbiamo incluso l'illustrazione dei Processi ETL, la Gestione avanzata dei dati, i Big Data e la Business Intelligence.
Restavano fuori dal nostro radar, come avevo già anticipato, ancora due altri temi - che in vario modo s'incrociano con i precedenti - e che mi ero ripromesso di trattare: la Data Science e la Data Protection che completano nell’insieme gli elementi conoscitivi utili ai lettori sul tema.
Il nome Data Science insospettisce/intimorisce un po’ i non addetti ai lavori, ma in realtà essa può essere considerata un settore interdisciplinare che utilizza una ampia varietà di metodiche e strumenti, diversi metodi scientifici e relativi processi, algoritmi e sistemi, tutti sostanzialmente orientati alla estrazione di valore dai dati.
Possiamo affermare, come avevamo già scritto, che il valore dei dati è rapportato alla catena dato - informazione - conoscenza.
E’ quest'ultima quindi il “prodotto" dell'applicazione della Data Science nei processi di Data Management.
Quello che caratterizza la Data Science non è perciò solo il fine ma sono i metodi molto sofisticati adottati.
In questo articolo voglio parlarvi della Data Science, rimandando ad un articolo successivo il tema della Sicurezza, declinato in termini di Data Protection.
Concentriamoci adesso sull’argomento: in realtà la si comprende meglio, concettualmente, se si osserva la Data Science sostanzialmente come un metodo di approccio agli obiettivi di conoscenza nel dominio di interesse e che, per farlo, adotta strumenti evoluti di analisi e comprensione quali lo advanced analytics e il machine learning.
Un esempio di obiettivi è quello di aiutare gli utilizzatori, nelle organizzazioni, in termini di predizione e di ottimizzazione dei risultati di business.
L’intento primo é probabilmente quello di modellizzare i fenomeni analizzati partendo da opportuni livelli di astrazione.
Possiamo citare, a titolo di esempio, alcuni metodi matematici e tecnologie digitali utilizzati nei diversi trattamenti di Data Science in una amplissima casistica applicativa:
- algoritmi di rilevamento delle frodi, nel settore pubblico, nelle assicurazioni, nei prodotti alimentari e/o farmaceutici
- modellazioni per scoprire fattori di non conformità sconosciuti che possono ostacolare i cicli di produzione ad alta precisione
- ottimizzazioni per prescrivere le migliori linee d'azione a fronte di decisioni che coinvolgono compromessi tra obiettivi e vincoli, ad esempio nel settore dei trasporti
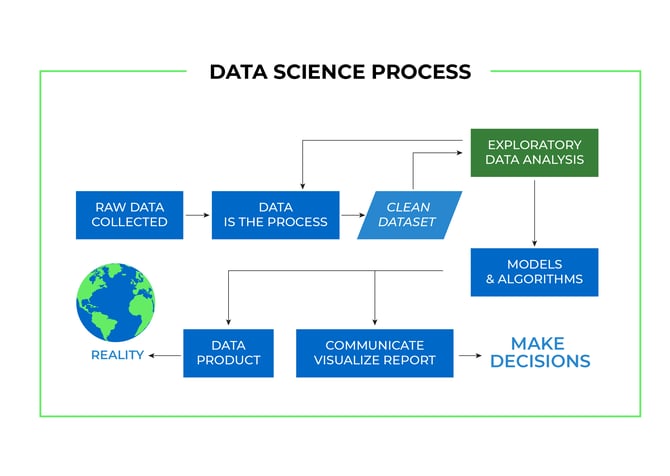
Ma, per poter realizzare questi obiettivi, dobbiamo partire dall'abilitatore fondamentale: esso è costituito dai data scientist.
Si tratta di specialisti ad alto livello di professionalità, che combinano competenze in varie discipline quali matematica/statistica, informatica, automazione, economia e marketing, capaci di analizzare i dati raccolti con le varie fonti digitali, quali il Web e gli smartphone, nonché da una svariata tipologia di sensori e da altre numerose fonti.
La data science è un settore giovane, che deriva dai campi dell'analisi statistica e del data mining.
Il data scientist si occupa di sviluppare strategie per l'analisi dei dati, esplorare, analizzare e visualizzare i dati, creare modelli con i dati utilizzando linguaggi di programmazione - quali Python e R - nonché implementare i modelli nelle applicazioni.
Il data scientist non lavora da solo, ma tipicamente in team.
I team di data science possono includere, oltre al data scientist, un analista aziendale che definisce il problema, un ingegnere informatico che prepara i dati e ne definisce le modalità di accesso, un architetto IT che supervisiona i processi e l'infrastruttura sottostanti ed uno sviluppatore di applicazioni che implementa i modelli o i risultati dell'analisi in applicazioni e prodotti.
La data science comprende la preparazione dei dati per l'analisi, inclusa la pulizia, l'aggregazione e la loro manipolazione per eseguire analisi avanzate: alle procedure e ai metodi della data scienze si applicano perciò i criteri concettuali e pratici già descritti dei processi ETL.
Le applicazioni analitiche e i data scientist possono quindi esaminare i risultati per scoprire modelli e consentire ai leader aziendali di trarre insight informati.
Si può quindi affermare, in senso generale, che la data science consente la trasformazione dell’informazione in conoscenza.
La conoscenza, nell’ambito delle aziende, risulta essere il fattore determinante per la messa a frutto strategica del patrimonio informativo all’interno dell’organizzazione e all’esterno di essa, in quanto facente parte di una rete digitale complessa e distribuita.
Esempi principali sono, per le aziende, le applicazioni avanzate del CRM e della Supply Chain, mentre per le organizzazioni non strettamente aziendali, si possono citare a titolo di esempio, l’orientamento delle opinioni pubbliche, le previsioni e simulazioni sui temi economici e di geopolitica, il controllo dei fattori epidemiologici e sanitari, per non citare le numerose applicazioni nell’ambito della ricerca scientifica nel suo complesso.
Data Science: rischio di sottoutilizzo
Le aziende basano sempre più le proprie attività su una preziosa raccolta di dati i cui volumi sono aumentati esponenzialmente: si stima che il 90% dei dati a livello mondiale sia stato creato negli ultimi due anni.
Spesso però i dati vengono conservati in database e data lake, per lo più inutilizzati.
I moltissimi dati raccolti e archiviati mediante queste tecnologie possono offrire vantaggi solo se si é in grado di interpretarli.
La data science, con le sue interpretazioni dei dati e delle informazioni, mostra allora trend e produce insight che le aziende possono utilizzare per prendere decisioni più mirate e creare prodotti e servizi più innovativi.
Forse il vantaggio più importante è che si consente ai modelli di machine learning (ML) di apprendere dalla grande quantità di dati con cui vengono alimentati anziché affidarsi principalmente agli analisti per capire cosa può essere scoperto dai dati.
I dati costituiscono in tal modo la base dell'innovazione, ma il loro valore deriva dalle informazioni e dalla conoscenza che i data scientist possono ottenere ed in base alle quali possono agire.
Continuate a seguirci!
Riferimenti
- https://it.wikipedia.org/wiki/Scienza_dei_dati
- https://www.google.com/search?q=machine+learning&rlz=1C1FERN_enIT817IT943&oq=machine+learning&aqs=chrome..69i57j0i67l2j0i512j0i67l4j46i512j0i67.6824j0j15&sourceid=chrome&ie=UTF-8
- https://www.ibm.com/it-it/cloud/cloud-pak-for-integration?utm_content=SRCWW&p1=Search&p4=43700068019640506&p5=p&gclid=Cj0KCQjwl7qSBhD-ARIsACvV1X08tw5MHZNPHgehzsHml1QXEQVDf8NztMUKW8bz5wChoP1WTUu-GSgaApZ9EALw_wcB&gclsrc=aw.ds
- https://blog.osservatori.net/it_it/data-scientist-cosa-fa-stipendio
- https://www.google.com/search?q=notebook+open+source&rlz=1C1FERN_enIT817IT943&oq=notebook+open+source&aqs=chrome..69i57j0i22i30l9.2445j0j15&sourceid=chrome&ie=UTF-8